
案例介绍
Map方法之后Reduce方法之前这段处理过程叫Shuffle方法之后,数据首先进入到分区方法,把数据标记好分区,然后把数据发送到环形缓冲区;环形缓冲区默认大小100m,环形缓冲区达到80%时,进行溢写;溢写前对数据进行排序,排序按照对key的索引进行字典顺序排序,排序的手段快排;溢写产生大量溢写文件,需要对溢写文件进行归并排序;对溢写的文件也可以进行Combiner操作,前提是汇总操作,求平均值不行。最后将文件按照分区存储到磁盘,等待Reduce端拉取。每个Reduce拉取Map端对应分区的数据。拉取数据后先存储到内存中,内存不够了,再存储到磁盘。拉取完所有数据后,采用归并排序将内存和磁盘中的数据都进行排序。在进入Reduce方法前,可以对数据进行分组操作。
案例图片
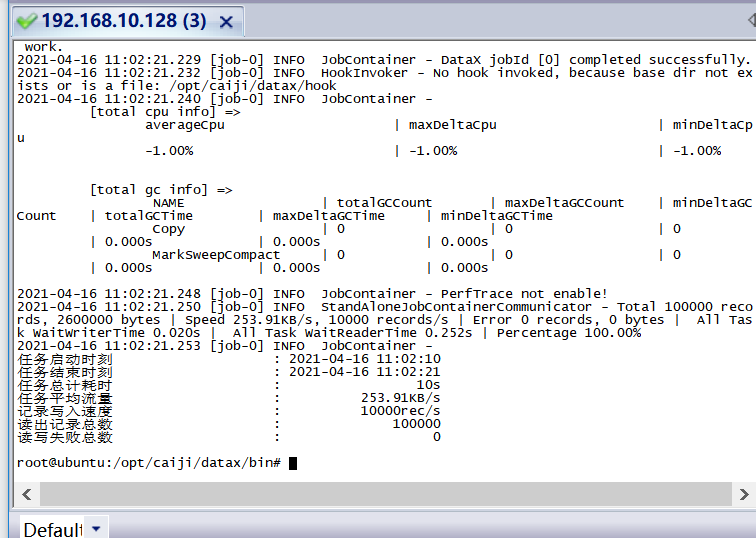
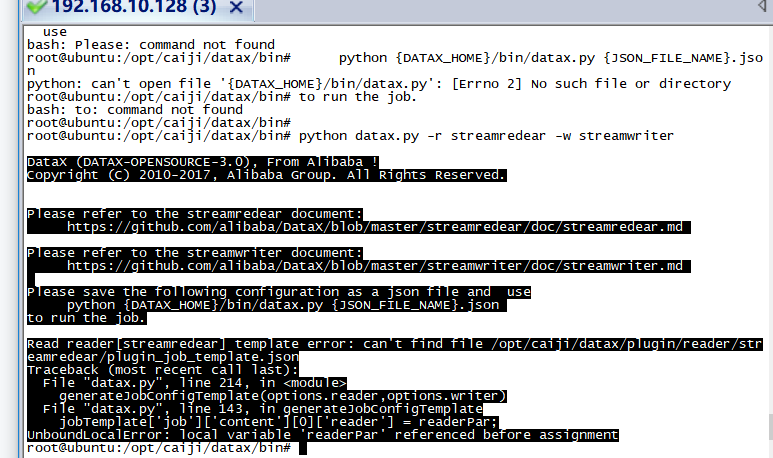
相似案例推荐
其他人才的相似案例推荐
-

万象云检索
1.开发了专利聚类的项目,根据专利数据对数据进行分词 并根据
-

万象云检索
1.开发了专利聚类的项目,根据专利数据对数据进行分词 并根据
-

可视化面板开发
在这些项目当负责根据UI设计师所给的设计图来编写出前端的可视
-

dhcp的攻击防范功能示例
a与b是二层交换机 c 是用户网关作为dhcprelay向d
-

大数据平台二期
大数据平台一期的基础上新增数据拆分平台、数据交换归档作业;迁
-

全球采购花费平台
全球采购花费平台是集团打破与海外分公司及收购企业的采购信息孤
-

全景网爬虫
关于全景网的爬虫案例,运用相关python 爬虫技术来爬取相
-

研发管理平台
内容: ● 使用vue配合element作为前端展示,完
-

研发小程序
内容: ● 使用vue配合element作为前端展示,完
-

猫眼电影TOP100
主要涉及一门语言的爬虫库、html解析、内容存储等,复杂的还
-

中国天气网数据爬取
爬虫知识,主要涉及一门语言的爬虫库、html解析、内容存储等
-

市域治理
市域治理可视化实战平台,是熙菱信息自主设计研发的行业产品,针
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

