爬虫小说阅读器

案例介绍
基于爬虫架构的小说阅读器
独立完成
2020年04月 - 2020年05月
成都
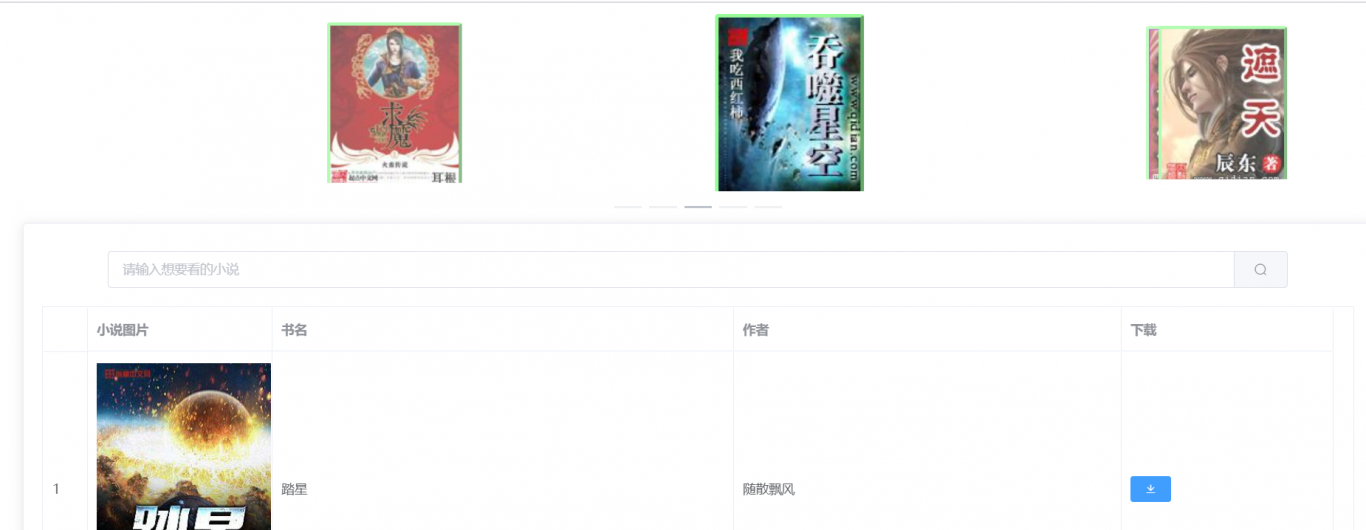
项目主要由node后端,vue前端,mysql数据库,python爬虫处理组成。 后端有八个接口,分别对应首页展示书籍;全部书
籍(带搜索和分页);章节信息注入;章节目录获取;小说内容暂存;小说内容获取;浏览记录写入;浏览记录读取接口。
前端使用vue和elemen ui实现,用到了抽屉组件,分页组件,轮播图组件,列表组件等。
前端使用cdn和gzip处理,路由懒加载等优化处理。
上线使用阿里云ecs服务器,rds数据库和oss存储
案例图片

相似案例推荐
其他人才的相似案例推荐
-

基于浏览器的网络爬虫系统
采用.NET技术实现的基于IE浏览器的数据提取和网页自动操作
-

全球反侵权网络侦测系统
全球反侵权网络侦测系统是一套实时侦测互联网视频发布平台各项视
-

重庆华新街垃圾分类小程序
项目名称:华新街垃圾分类小程序 项目简介:项目包括H5小程
-

新疆第十二师一体化政务系统
项目名称:新疆第十二师一体化政务系统 项目介绍:类似于市面
-

salary
保密原因没有截图,系统细节不能透漏,只能上传工作照 软通动
-

电霸拼多多软件
项目描述:拼多多运营最优秀的大数据分析系统。通过爬虫抓取拼多
-

招聘职位数据采集
采集数据,招聘网上招聘岗位各项数据。 采集数据,招聘网上招
-

全网舆情数据采集
采集互联网舆情数据,主要包含媒体新闻网站、APP,微信,微博
-

ungm联合国采购平台
在登录中实现了微信扫一扫登录以及账号密码登录; 填写表单过
-

内部软件应用
内部软件应用,内网部署.无法在外网访问,并且已经历多家公司有
-

内部软件应用
属于企业内部应用,无法在外网访问,并且以在经历多个公司 有些
-

西山居
爬虫 协议爬虫 协议爬虫 协议爬虫 协议爬虫 协议
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

接收人才推送

联系需求方端客服