
案例介绍
沃保保险网 项目描述: 项目概况: 爬取沃保网全国各个保险公司下皇冠会员、钻石会员分类下的所有保险代理人的姓名、微信二维码图片、城市、保险公司、个人网站、保险从业资格证号等信息,其中保险从业资格证号信息从详情页获取,其他均从列表页即可获取 遇到问题及解决方案如下: 1、需要爬取的数据经过分析,得出是所需要的数据可
通过POST请求并携带参数得到,考虑到数据量较多,采用scrapy-redis进行爬取,因为该框架实现url和数据去重、持久化、分布式比较方便,构建RedisSpider分布式爬虫,爬取更快 2、下载的微信二维码图片有些因为格式原因无法打开,筛选出来,通过os模块对这些图片批量重命名加后缀 3、每个代理人的个人网站详情页页面模板不太一样,但是有三种页面的HTML结构,在提取资格证号的时候,需要编写三种页面的xpath提取代码,进行三次判断,对应每种页面的HTML特征,适用对应的提取方法 4、考虑网站能否打开和打开时间问题,一般需要加异常判断、超时、retry等减少报错 5、数据按保险公司分表存储于mysql,减轻一个表的负载 6、爬取的数据通过redis集合、sha1加密,等技术手段,实现新提取的数据保存,已爬过的数据更新的断点续爬功能。 7、构建USER-AGENT池,使用随机代理,随机IP采用阿布云动态IP 8、使用logging模块编写监控程序进行爬虫监控,并根据日期定向输出日志到log文件 个人职责: 编写爬虫程序,想出反反爬策略,数据清洗,分表存储,维护代理ip池
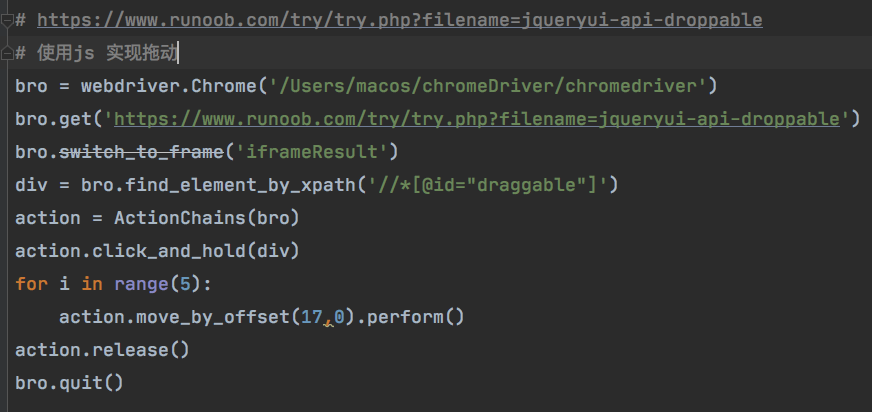
案例图片

相似案例推荐
其他人才的相似案例推荐
-

自然语言处理
自然语言处理,英文Natural Language Proc
-

基于深度学习的语义分割
语义分割一直是计算机视觉中十分重要的领域,随着深度学习的流行
-

合成器
根据原理图,独立开发控制该产品的嵌入式软件,软件结构包括bo
-

量脚神器
负责整个安卓app(50%的时间): 1.用c++ t
-

基于stm32音频会议系统
利用qt编写的音频服务器,主要是作为stm32开发的音频会议
-

metapro
云端文件管理系统,项目脱胎于著名云端项目nextcloud,
-

T8足球笼训练系统
我主要负责终端AI开发,与小程序架构设计 终端开发包含
-

浙江移动手机营业厅
提供话费,流量查询等业务提供话费,流量查询等业务提供话费,流
-

浙江移动手机营业厅搜索业务
提供话费,流量查询等业务提供话费,流量查询等业务提供话费,流
-

EV Data Platform
Alliance EV Data Platform 电动车
-

remote driving
remote driving 主要是实时 监控 和了解
-

驱动器上位机调试软件
实现功能:PC端与硬件设备——驱动器通讯实现数据交互和控制,
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

