
案例介绍
本项目将数据预处理,设计DNN模型,利用反向传播(BP)算法构建具有很多隐层的机器学习模型,用预处理的大量训练数据来学习模型特征,从而保证预测的准确性达到要求。
我们将药物Irinotecan的未知数据(其在317个细胞系下的反应数据已知,187个未知)作为预测目标,将其他药物的相应的317个数据看做输入,187个数据作为目标输出,来训练神经网络。
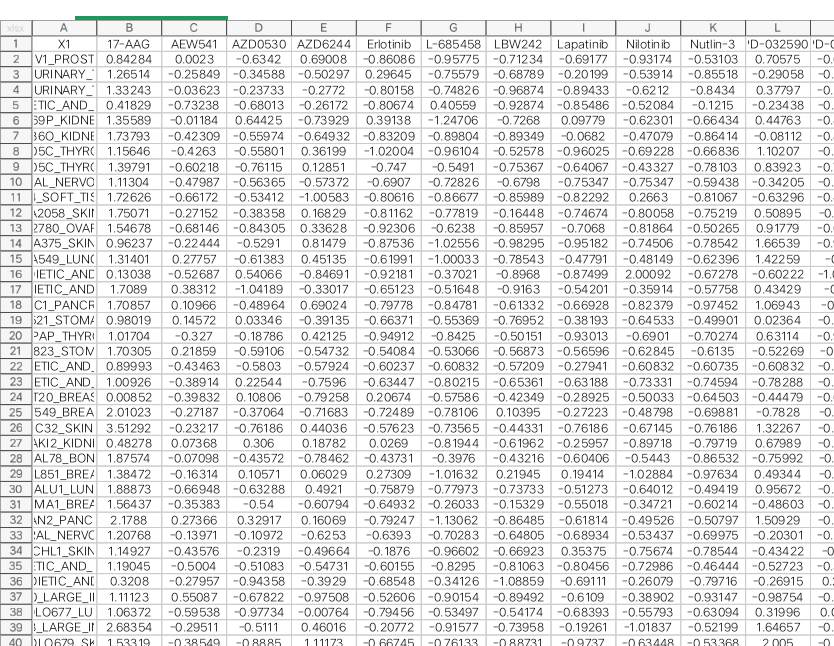
用python首先导入数据,用pandas库函数导入csv数据,然后转化为numpy矩阵,大小为[504,23](从0开始),将数据分为训练集和测试集,317组为训练集,187组为测试集。每组数据有23个属性,训练集中的标签就是药物Irinotecan对该组细胞的药性,测试集中标签未知,为要预测的值。将训练集分为训练集和验证集,因为数据集较小,用k折交叉验证法验证神经网络的精度(使用mse损失函数,监控指标mae平均绝对误差),网络包含两个隐藏层,每层64个隐藏单元,最后一层只有一个单元(没有激活,标量回归)。选取的折数为4,每折训练500次。最终输出预测值,即药物在187个细胞里的反应,另外输出平均绝对误差(为预测值与目标值的差距)。
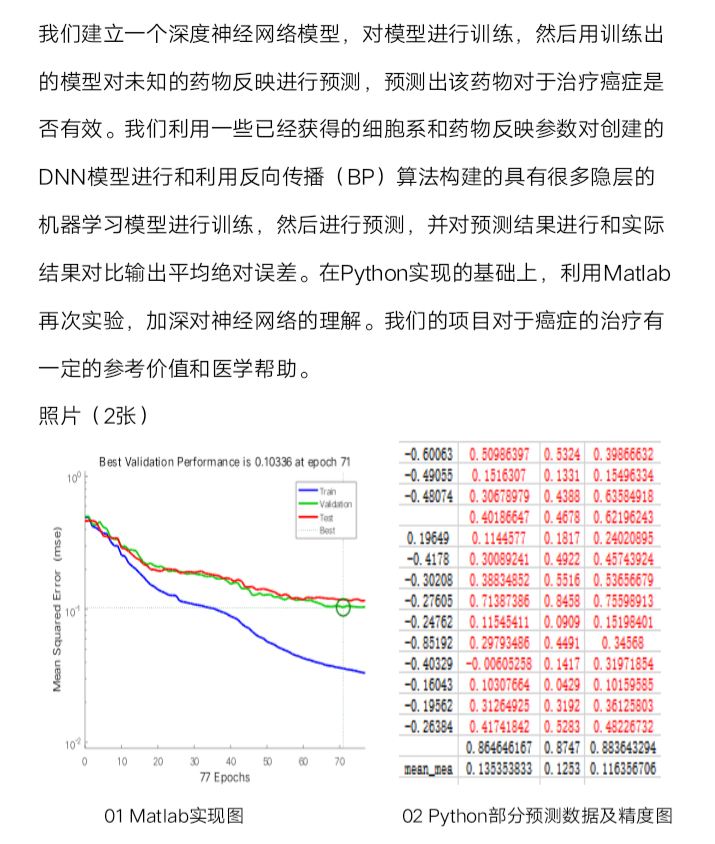
在Python实现的基础上,利用Matlab再次实验。
Matlab实现过程:构建了三层神经网络,每层20个神经元,选择了19个样本来训练神经网络;选择了2个验证样例用来衡量网络泛化,并在泛化不再改善时停止训练;选择了2样本用于测试,测试集对神经网络的训练没有影响,因此可以在训练完成后独立地测量网络性能。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

药品采购
java后端使用ssm+spring boot 前端使用vu
-

瑞通数字化平台
3D打印智能平台 为3D打印平台制作管理业务系统,使用jav
-

舌侧3D数字口腔系统
使用C#以及Python通过算法为牙科3D打印加工的自动模型
-

中健健康管理
一个针对医疗下乡的体检车系统,提供体检档案分级管理,迅速采集
-

LIS血流变仪器的切变率图谱的C#程序
使用C#开发,根据从血流变仪器获取的检测结果数据,按照血流变
-

万方数据检索平台
万方医学网项目中负责前端开发,主要负责医学网检索服务这一块内
-

碧沙康健
1:负责该项目前期需求分析,画模块分布图 2:技术选型,确
-

智能输液系统
1.该系统可以对病患输液过程中的输液情况进行实时监控,在出现
-

医疗软件应用开发与咨询
•某958高校大学医院:某958高校大学医院需求搭建一套数仓
-

禾健康公众号
一个方便用户购买体检套餐, 简化体检流程的公众号, 用户能直
-

1药百科
微信小程序:1药百科 独立开发完整小程序,包含药品信息、医
-

全场景疫情信息采集系统
项目:全场景疫情信息采集系统 技术框架:安卓采集端、PC采
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

