
案例介绍
- 使用技术:Requests,Scrapy, RabbitMQ, XXL-JOB, Xpath,正则表达式,SimHash,分布式,搭建网站采集配置化页面
- 项目描述:主要采集光伏太阳能相关的网站以及相应技术网站的数据,保存到内部的MongoDB;商情系统通过对特定信息的检索来给客户进行数据的展示,以了解当前技术以及相关政策法规。
- 项目实施:
- 使用requests 多线程 多进程 搭建分布式爬虫框架(将下载器,调度器,解析器,数据处理模块进行解耦,信息的交互使用队列)来实现数据的高效稳定采集,并搭建采集配置页面进行网站配置来进行数据的采集而不用再写爬虫脚本来实现数据的采集;
- 针对反爬措施,搭建 ip池,cookie池,账号池,以及Splash等服务
- 其中使用simhash局部敏感hash来进行数据的去重操作,
- 任务的优先级调度使用XXL-JOB框架。
案例图片
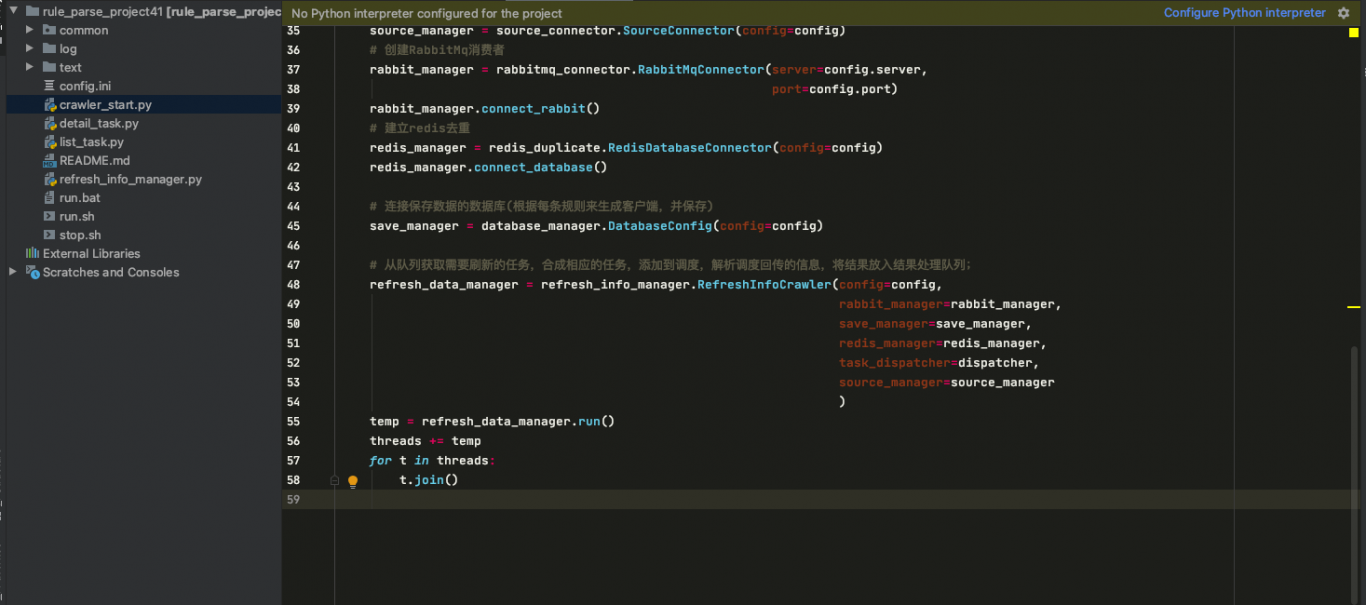
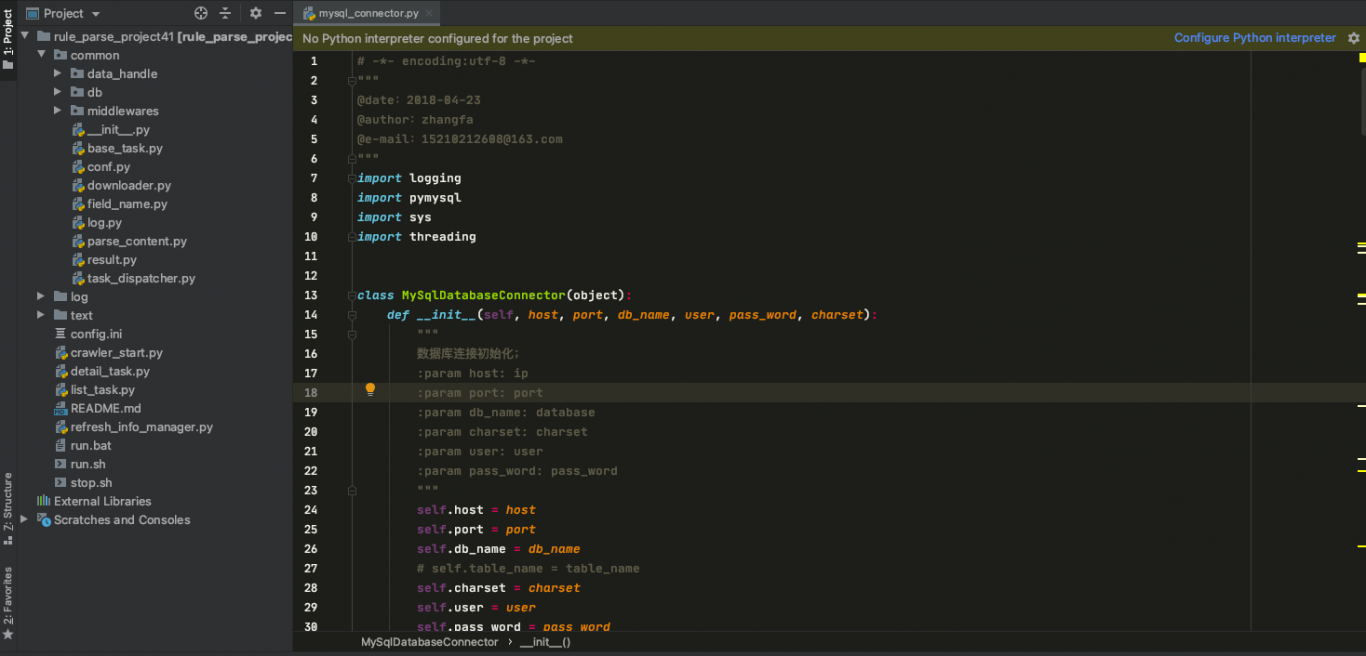
相似案例推荐
其他人才的相似案例推荐
-

移动信息平台
移动办公系统,jsp网站,sdk1.8,整合springmv
-

Face用户画像
BI数据分析可视化系统,可根据用户定制选用多种图表展示用户画
-

实时平安墙
在大屏上用图表动态展示后台数据实时变化,主要负责前端框架选型
-

财服通
项目介绍: 公司的19年主推项目,用于管道水工的日常工作任
-
")
ROOMS(APP)
该APP主要是用于某电厂的培训与考核管理,我主要负责的功能:
-

运行人员核安全文化素养评价与诊断系统
我在该项目中负责web前端开发,主要的工作是 1、根据u
-

公司武器库
有各种组件,为组内共同开发,本人负责维护此组件库,运用svg
-

嘟嘟作业
息进行人工审核,对于不符合条件的申请记录进行打回,并提供具
-

BPM日常维护管理平台
本作品主要是针对bpm系统日常运维提供快速分析和解决问题提供
-

Api网关-ResfulWebApi接口
1、根据公司的信息化建设的战略规划,自研开发一套高内聚的中心
-

OA医疗办公系统
该系统为公司内部办公系统。 拥有人员管理、客户管理、财务模
-

某房产数据获取
获取某房产的整站数据,获取其房屋出租、出售价格,地段等信息,
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

