基于豆瓣知识图谱的在线问答系统

案例介绍
一、 豆瓣信息爬取和知识图谱构建
1、使用python scrapy爬取豆瓣读书(https://book.douban.com/tag/?view=type&icn=index-sorttags-all)下的图书基本信息,包括:类别、名称、作者、出版社、出版时间、价格、评分、评价人数、内容简介。数据量不小于5万。
2、使用neo4j构建图书知识图谱。实体结点包括:图书、作者、评分、类别、出版社。图书属性:出版时间、价格、内容简介;评分属性:评价人数。
二、问答系统功能实现
1、问句理解选择基于模板匹配方式,通过朴素贝叶斯分类器对用户问句分类匹配查询模板。
2、命名实体识别采用Word2Vec字向量模型、BiLSTM-CRF模型,构建Cpyher查询语句。
3、功能优化:模糊查询、联系上文查询。
三、web前端展示
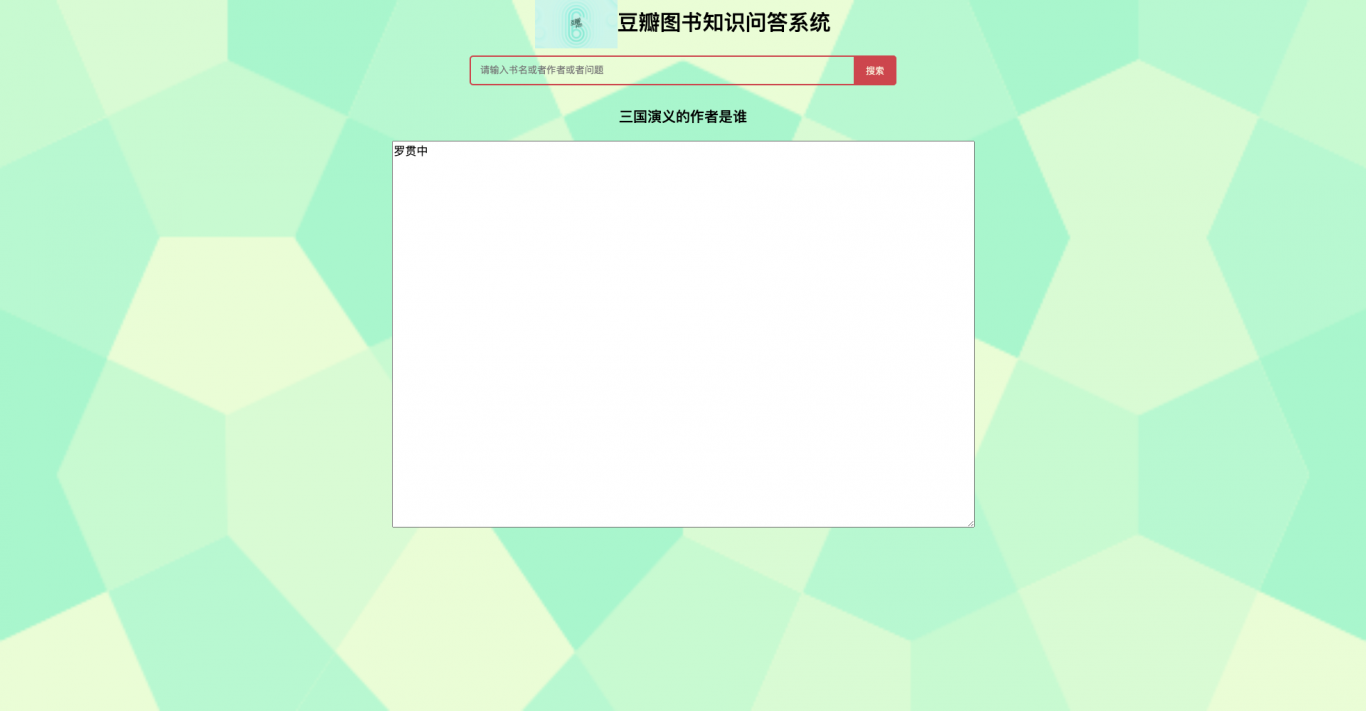
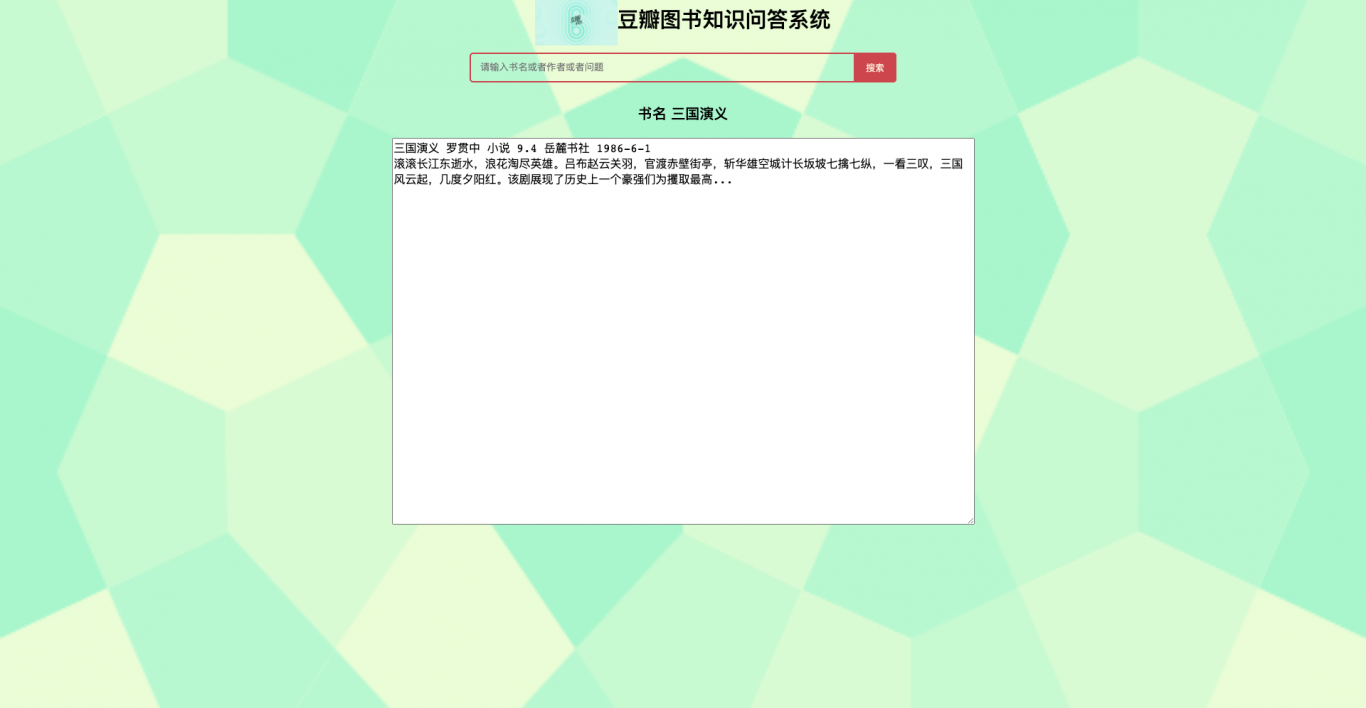
1、使用Django构建web问答页面:logo图片、标题-豆瓣图书知识问答
2、热门问题模板预设
3、问题输入框、查询结果框。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

无人机侦测
项目描述:ad9371 +fpga + atmel 平台实现
-

兰州网络公司
根据设计师最终呈现给客户的设计稿或是脑图,提前确认项目框架、
-

桥梁监测系统
采用静力、锚索测力计、应变采集仪多种传感器对桥梁的各项数据进
-

freeswitch外呼平台搭建
搭建完整的freeswitch平台,并提供相关rpc调用接口
-

freeswitch外呼平台搭建
搭建完整的freeswitch平台,并提供相关rpc调用接口
-

智能语音催收
1.与VUI人员讨论设计的可能性,并负责实现错综的语音交互。
-

物体轮廓提取
本作品为物体的轮廓提取,可以视频或者图片的轮廓。这个作品是我
-

分布式爬虫
基于 Django 框架,python的 Requests、
-

美团外卖爬虫
取美团美食移动端 深圳地区店铺的信息,包括:店铺名称、分类、
-

彩票随机选号
本人偶尔路过买一下彩票,所以做了一个随机选号的应用,用手机端
-

无人机
无人机是多年前开发的,主要使用的是 google 开源的 T
-

golang gin后端api
jwt登录,restfulapi, 密码加密加盐md5加密
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

