
案例介绍
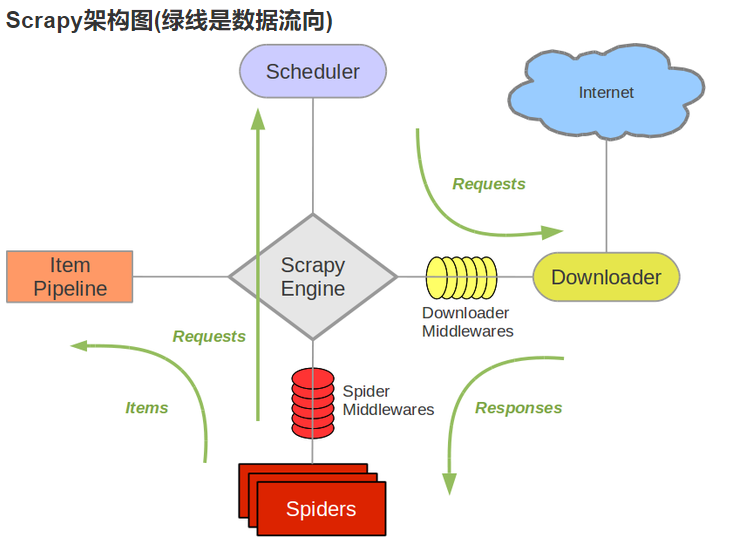
Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件。[1] [2]
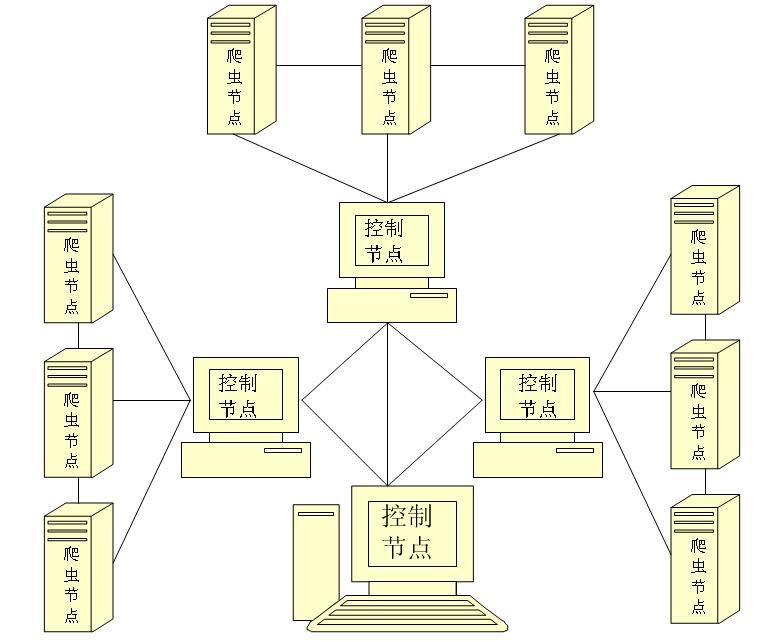
案例图片
相似案例推荐
其他人才的相似案例推荐
-

lego销售情况分析
项目介绍 收集数据,通过乐高在淘宝&天猫的销售情况
-

集客管理系统
系统需要给很多个客户使用,同时也要统计客户的网站的访问流量等
-

某平台订单数据分析
项目介绍: 对当天销售数据进行数据分析,了解大家电在平台的
-

某交通大数据分析平台
后台框架基于Java语言和Spring Boot框架,前端技
-

在线车辆状态监控系统
本项目基于Java SpringBoot框架,采集现场车辆传
-

招商管理系统
随着智能信息化和移动信息技术的发展,信息化管理的便捷化和智能
-

项目管理平台
该项目是一个项目管理的项目,主要内容,涵盖了PMP中常见知识
-

移动端自动化
1、使用Python + Appium进行搭建app自动化框
-

web端自动化
1)参与需求分析会议,制定测试方案和计划、设计测试用例、分配
-

问卷调查系统
项目简介: 本系统主要实现最为普遍的问卷调查,包括问卷管理、
-

python爬取数据并在网页展示
前端使用vue+vuerouter+vuex+element
-

电商后台管理系统
使用vue+vuex+vuerouter+axios+ech
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

