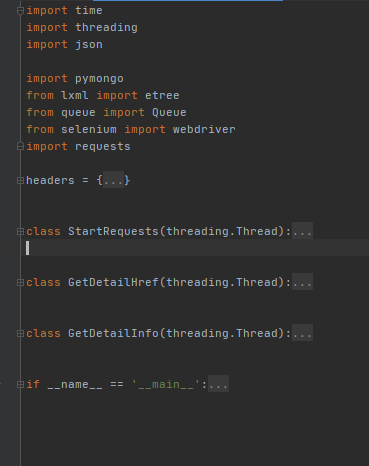
爬取亚马逊网站

案例介绍
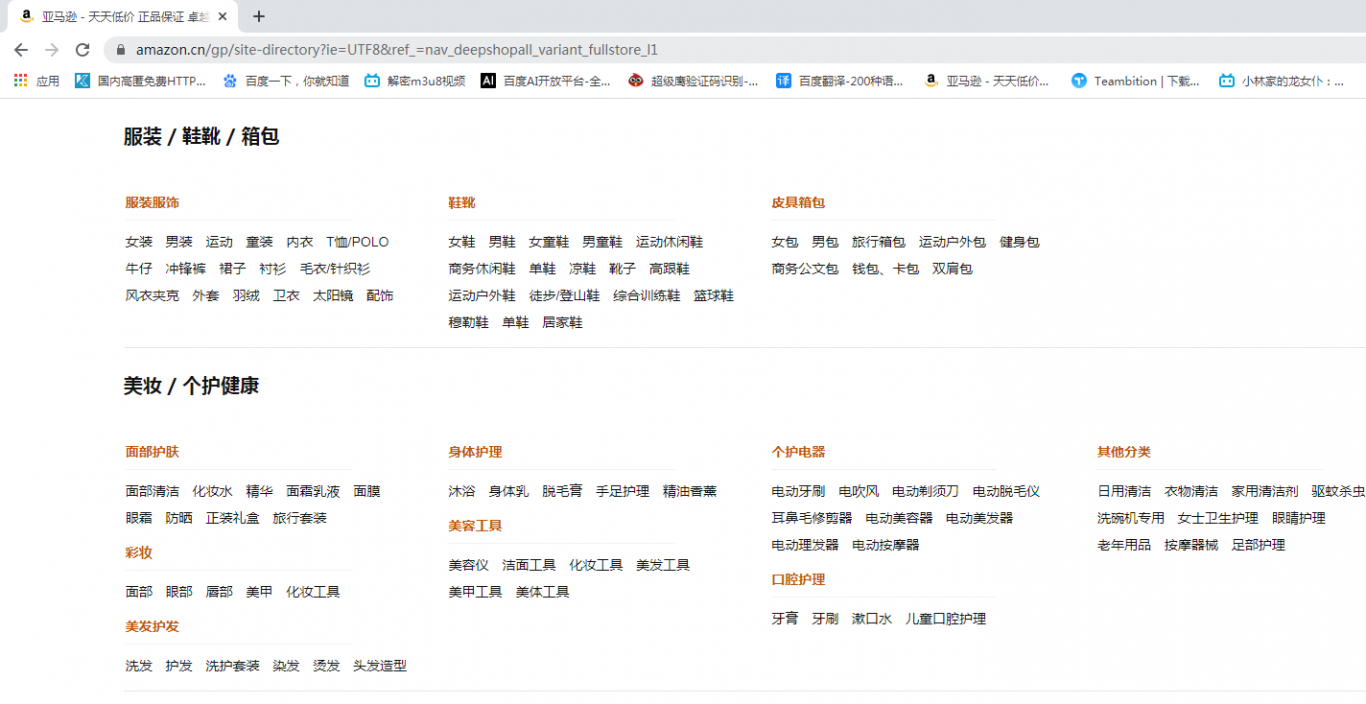
商品分类信息:
通过requests请求商品分类页面,用xpath分析页面获取亚马逊上所有的商品分类的大类,小类及其url ,保存在一个json文件中备用
获取商品小类分页:
请求分类url,获取商品的列表页,用xpath分析此类商品的列表页共有多少页,分析分页url的请求参数,建立需要请求的url队列备用
获取商品详情url:
请求商品分页中的每一个url,得到不同的商品列表页,用xpath分析这个页面得到每一个商品的详情页面的url,放入队列中备用
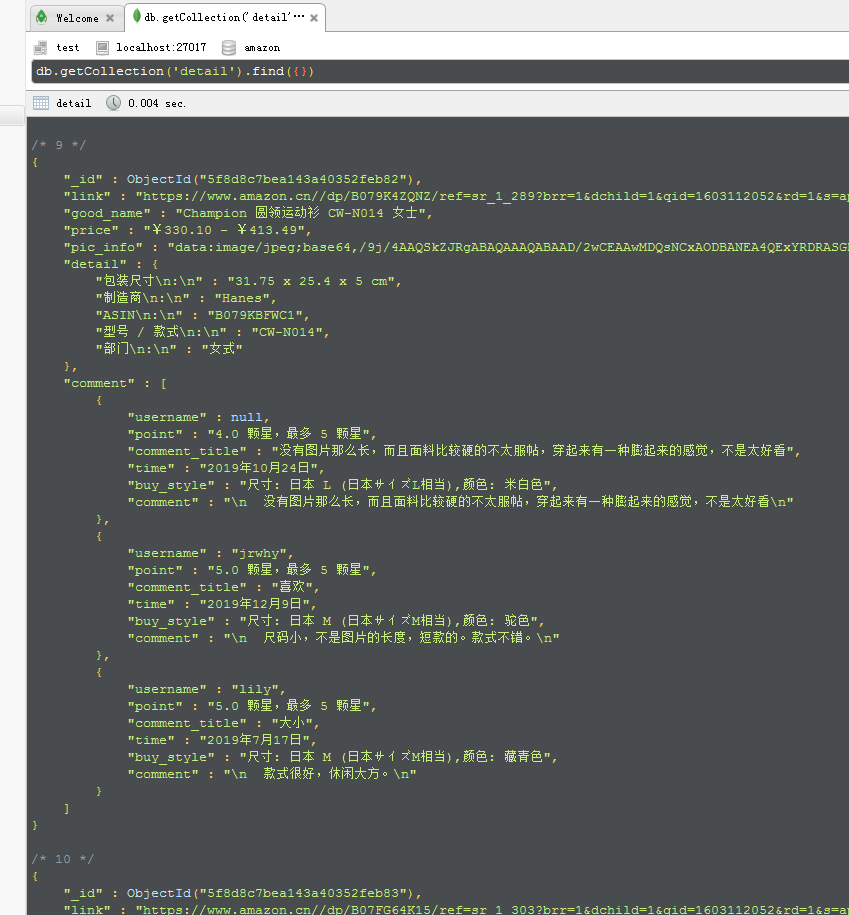
获取商品信息:
请求每一个商品详情页url,获取商品的详情页面。使用xpath对页面进行分析,获取商品名称,价格,参数列表,页面上评论列表,评论包括用户名称,打分,评语,购买的商品名称,下单时间。
解决反爬,只加入user-agent,有的页面会弹出验证码,并提示开启浏览器cookie功能。使用自己的账号密码登陆后,在请求头加入cookie进行模拟请求。仍然有验证,使用selenium+phantomjs(仍然有验证,自动使用Chrome)获取页面信息。最终将爬取到的信息放在MongoDB中,如遇页面信息提取错误,会生成一个error.log日志文件详细说明哪一个url请求出现了错误,方便进行再次请求获取数据,甚至可直接读取,使用正则匹配到链接直接进行访问。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

raydata
RayData个人版是一款功能强大、操作简单的免费数据可视化
-

ETL相关
数据的ETL,通过工具或脚本,python脚本同步,Data
-

应用统计分析
移动App数据统计分析产品,帮助移动开发者收集、处理、分析第
-

数据采集平台
采用flask+vue完成数据采集平台,可以采集json数据
-

数据采集
完成天眼查和企查查采集,解决网站的点选验证嘛和拖动验证码,列
-

山西太原资产管理系统
担任项目负责人,工作包括: 1、入场客户公司和客户进行需求
-

长安新能源项目
该项目本人全程参与,负责项目架构,公共组件,类库的编写,该项
-

重庆电力工程公司项目
电力工程公司项目主要是用于工程项目统计,上班打卡,工程记录,
-

车辆预警系统
项目简介 针对正在运营的约10万辆车,通过实时采集的监控数
-

数据可视化
项目简介 采用自然的方式呈现数据,为车企提供一个运营车辆的
-

数据分析平台
数据分析平台主要是对各类数据进行汇总,并进行数据清洗、分析,
-

EPS数据平台
采用前后端分离的开发方式,本人负责作品的全部前段工作。主要功
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

接收人才推送

联系需求方端客服