
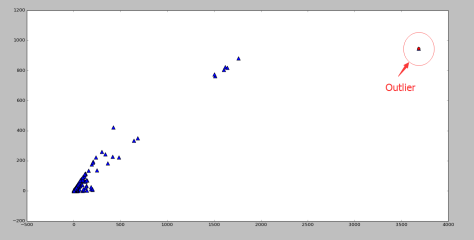
案例介绍
异常点检测的目的是找出数据集中和大多数数据不同的数据,常用的异常点检测算法有以下几类:
第一类是基于统计学的方法来处理异常数据,这种方法一般会构建一个概率分布模型,并计算对象符合该模型的概率,把具有低概率的对象视为异常点。比如特征工程中的RobustScaler方法,在做数据特征值缩放的时候,它会利用数据特征的分位数分布,将数据根据分位数划分为多段,只取中间段来做缩放,比如只取25%分位数到75%分位数的数据做缩放。这样减小了异常数据的影响。
第二类是基于聚类的方法来做异常点检测。这个很好理解,由于大部分聚类算法是基于数据特征的分布来做的,通常如果我们聚类后发现某些聚类簇的数据样本量比其他簇少很多,而且这个簇里数据的特征均值分布之类的值和其他簇也差异很大,这些簇里的样本点大部分时候都是异常点。比如BIRCH聚类算法原理和DBSCAN密度聚类算法都可以在聚类的同时做异常点的检测。
第三类是基于专门的异常点检测算法来做。这些算法不像聚类算法,检测异常点只是一个赠品,它们的目的就是专门检测异常点的,这类算法的代表是One Class SVM和Isolation Forest.
案例图片

相似案例推荐
其他人才的相似案例推荐
-

“中青杯”数学建模大赛
“中青杯”全国性数学建模大赛
-

“中青杯”数学建模大赛
“中青杯”全国性数学建模大赛
-

小样本牛肉品质分级数据集制作研究
校级创新项目:小样本牛肉品质分级数据集制作研究
-

知识图谱
上面图片并不是我参与的项目,我们目标和其类似,我主要负责图谱
-

文本分类
1)完成数据预处理:取图片上面1/3并由tif格式转为png
-

OPPO主题图标设计
参加的OPPO主题图标大赛,主要是图标的绘制,在站酷搜索 普
-

厨房实验室
独立开发 1、前后端分离模式,Springboot+Vue
-

厨房实验室
独立开发 1、前后端分离模式,Springboot+Vue
-

arm 4412开发板uboot
业余时间,学习arm开发板,独立完成uboot适配,串口调试
-

无作品
testestsetsetstsetsettestestse
-

测试报告
这个测试报告主要师针对财务报表、管理报表从创建人录入到审批驳
-

测试方案
通过测试方案针对系统做出相应的验收标准,在执行的过程中,根据
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

