
案例介绍
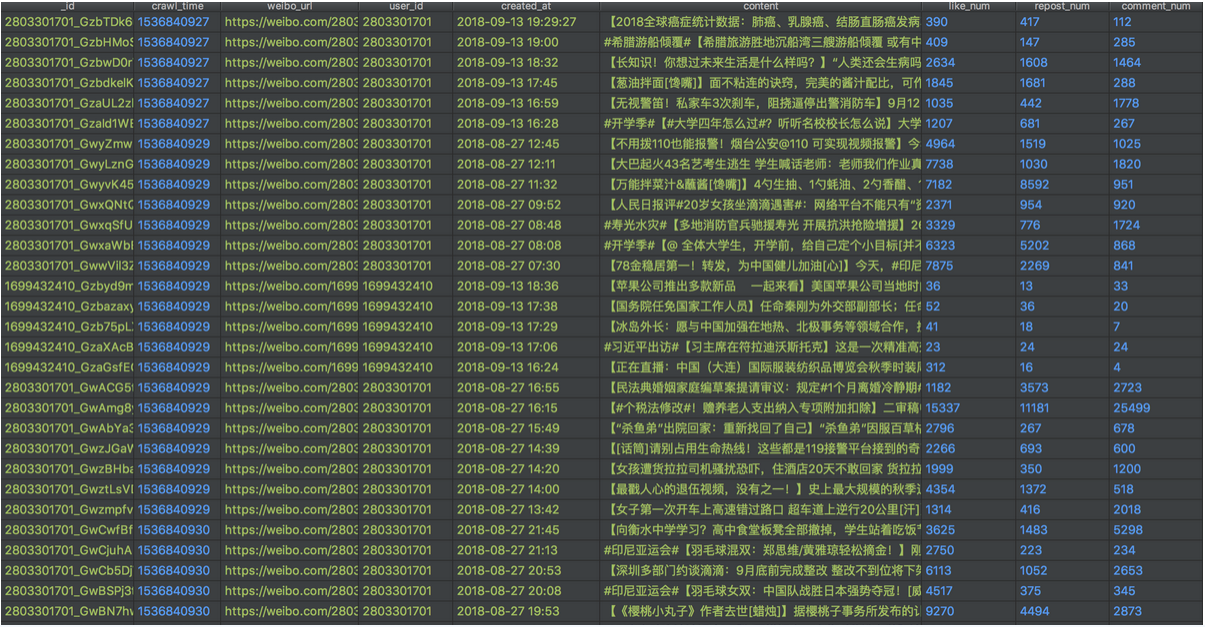
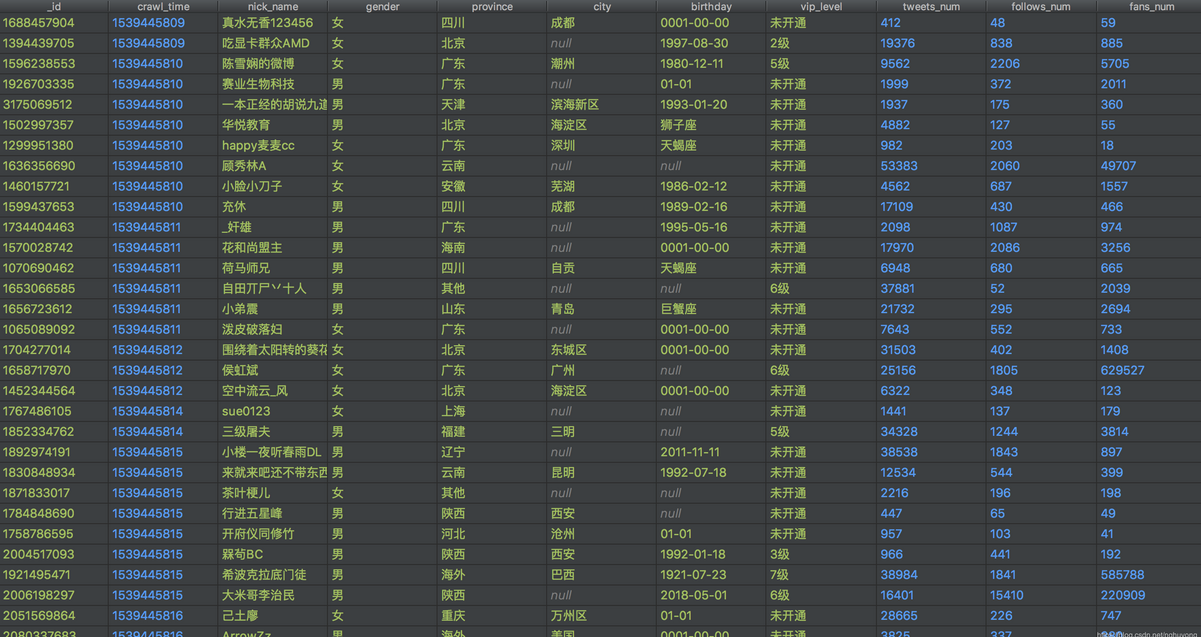
对于新浪微博的用户信息,和微博信息做爬取,构建爬虫系统
架构主要分两部分,下载器(Downloader)和提取器(Extractor)。下载器专注于数据的下载,可为下载器配置UA池或fake_useragent、cookie池、代理IP池(需要本地维护),不会做任何数据处理任务,下载成功后将数据写入Redis中定义好的Response List,并将用于下载的Request写入Dupefilter;提取器就会从Response List中拉取Response进行解析,不同网站使用不同key存储List。这里使用Redis作为Response中转是因为当运行的下载器数量较多时,返回大量的Response不一定能被提取器及时解析入库(数据库存储量达到一定级别后,磁盘IO可能大于网络IO),若放在内存中可能由于程序意外停止而丢失已经下载的Response(未入库)。
Dupefilter:使用BloomFilter可以有效节省去重集合对内存的消耗,取Redis中的256M字符串可对9000万条Url进行去重,漏失率为1.12e-04,漏失率和去重Url的数量关系可参考基于Redis的Bloomfilter去重,也就是说漏失率是可以控制的。
Request Queue:此队列可采用Redis的List或Zset数据类型实现,前者实现FIFO和LIFO队列,后者实现PRORI队列
Downloader和Extractor都可以分布式部署,只需配置好Redis服务的网络地址。两者的多线程部署有助于充分利用单机的带宽资源,CPU利用率提升可能不明显,爬虫始终是偏IO密集型的活动。
Request和Response:Request对象可作为一个字典来存,字典包含请求的url、cookie、headers、body、params、method以及others属性,Response也作为一个字典,包含下载到的html、cookies、headers、url以及others属性;这会有利于复杂页面的抓取。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

非个人作品不便展示。
非个人作品不便展示。非个人作品不便展示。非个人作品不便展示。
-

非个人作品不便展示
非个人作品不便展示。非个人作品不便展示。非个人作品不便展示。
-

御宝羊奶商城
负责御宝羊奶官方商城的开发与维护,前端后端都要。前端HTML
-

湘西人才网
负责湘西人才网的开发与维护,前端后端都要。前端HTML,JS
-

连锁店erp系统
1. 全国所有连锁店使用的一套ERP系统,包括基本的产品进销
-

芯迈宝
这个是一个微信小程序,获取微信的步数可以兑换成游戏币,游戏币
-

爱订房
爱订房是2018年推出面向全国用户的0差价订房APP,为用户
-

萌妈返利
萌妈返利是一款电商导购平台,用户通过萌妈返利去各大电商平台下
-

维拉度假
维拉度假·Villaday,致力于度假、聚会、轰趴的资源整合
-

美甜美选商城
本人任此项目的主要负责人,及主要开发人,并担任后期的主要维护
-

卡速车品
卡速车品商城专注于汽车及汽车后市场服务,致力于为车主打造一个
-

万果田园
万果田园是“体验式农业”手机软件,致力于解决用户对优质安全农
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

