
案例介绍
这是我独立全程完成的一个医疗与健康领域文本主题建模和分析的项目:
本人所在行业是医疗与健康行业,所以大部分的项目都是和医疗相关。数据是近30年来的医疗与卫生年报,文件都是OCR的PDF文件,每个文件比较大,有的多达1000页,少的也有200页。 目标对这些年报进行主题建模和分析。
目。
1. 转换PDF,word到txt文件
2. 对数据进行预处理(停用词,Abbreviation extraction, Lemmatization,Phrasing 等等)
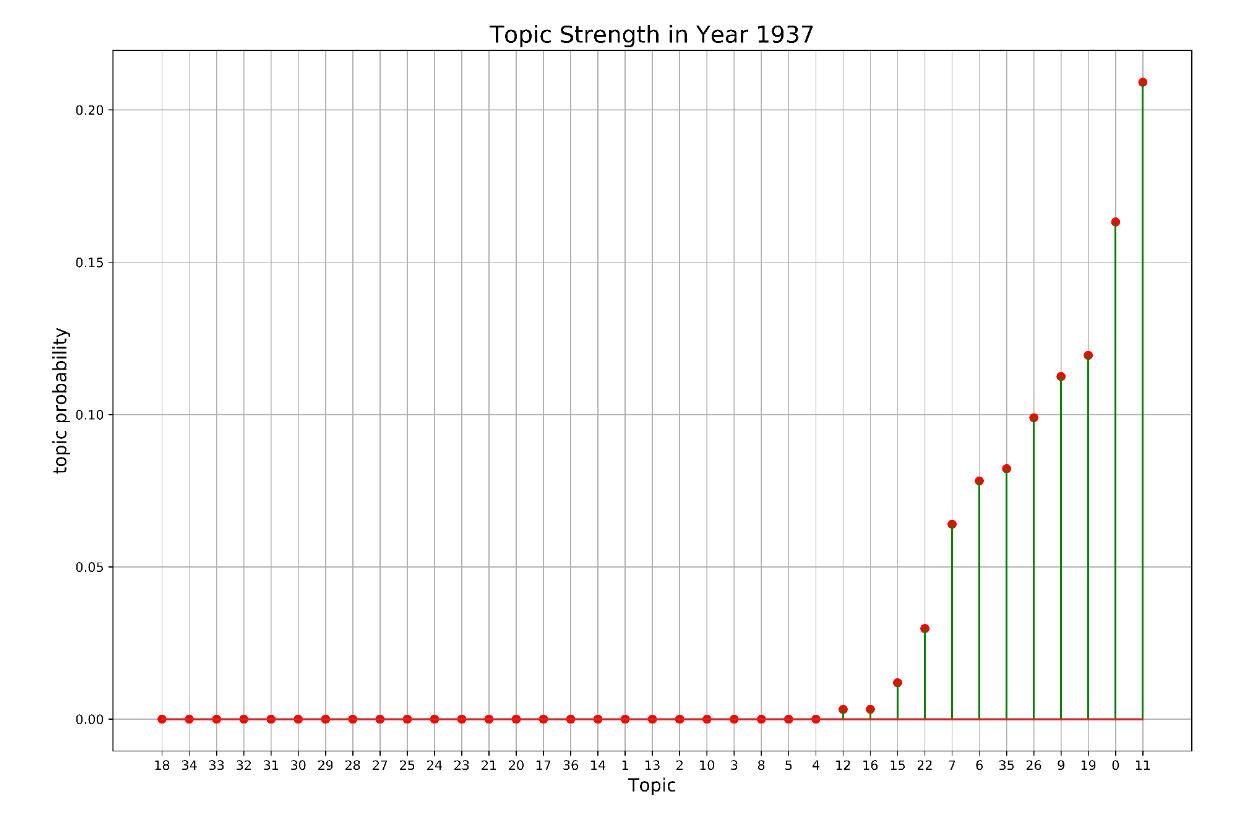
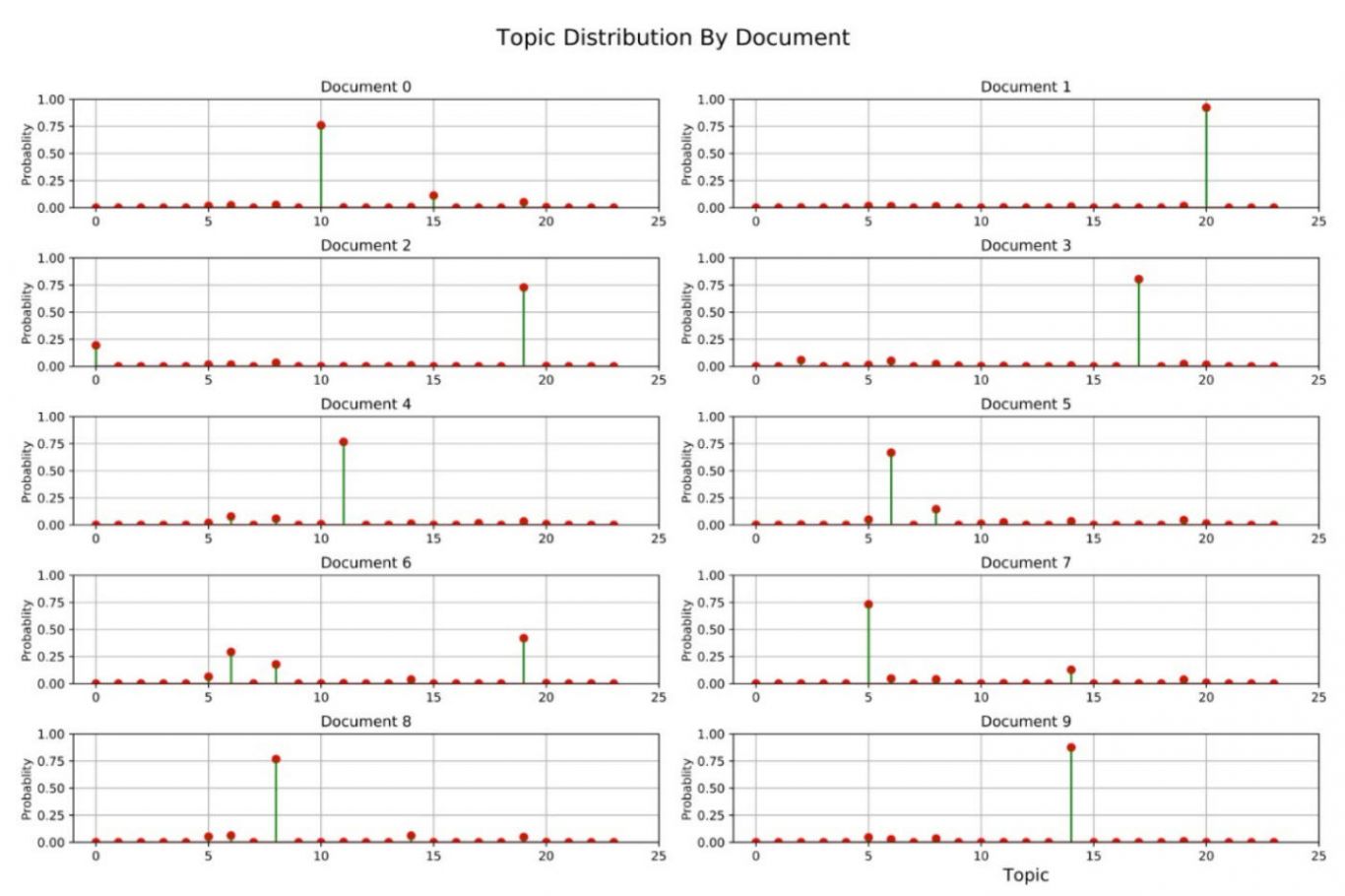
3. 对这些文本使用LDA模型进行主题建模
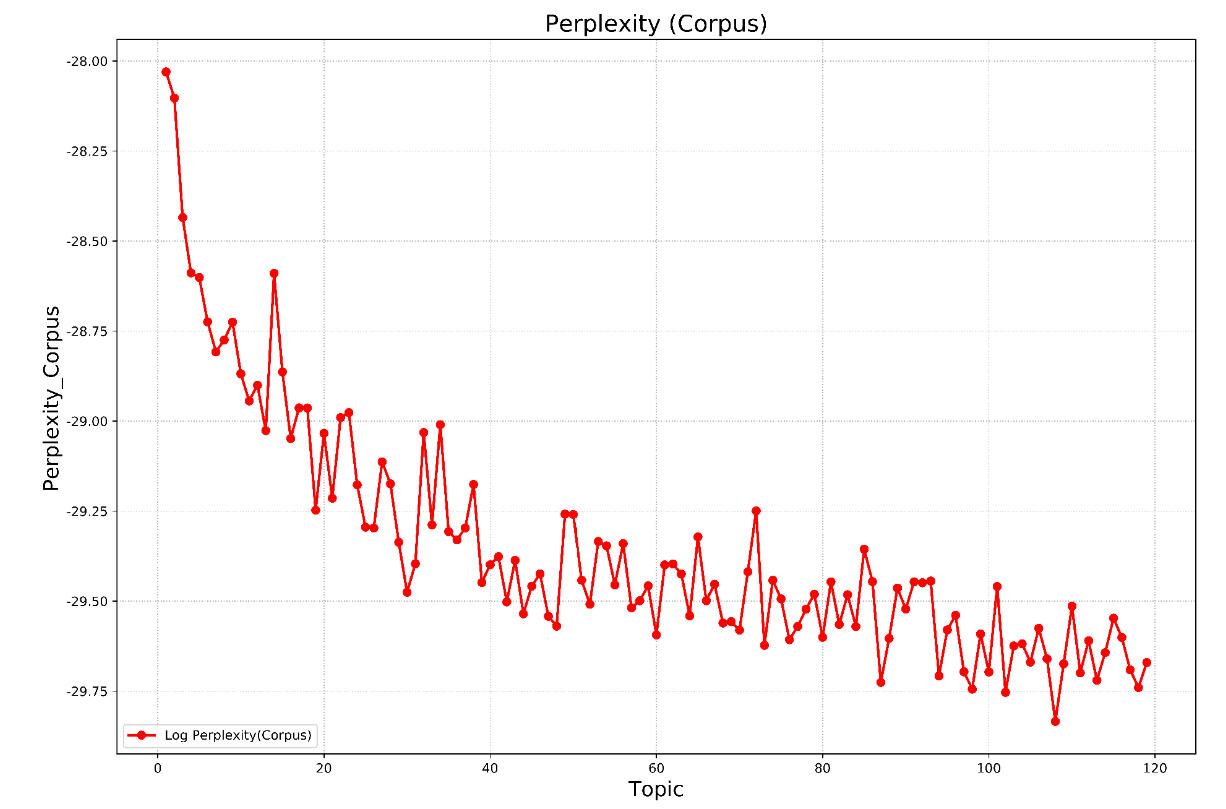
4. 计算perplexity值选择最优的主题数目
案例图片
相似案例推荐
其他人才的相似案例推荐
-

合同制约,不可公开
一人负责该网站前后台以及数据库搭建,编写,测试,上线,页面主
-

上海某医院系统
需求分析、数据库设计、模块开发、测试、修复bug,解决幂等问
-

食品检测
提供食品安全抽检业务全流程管理功能,对食品安全数据进行深度挖
-

食品检测
提供食品安全抽检业务全流程管理功能,对食品安全数据进行深度挖
-

惠食安
通过打造全链条、实时、动态、闭环式联动的食品安全管理机制并信
-

全民战疫
最近武汉肺炎 2019-nCoV来势汹汹,全城戒备。虽然是一
-

MIC-1000
项目为医疗领域某开发设备,本人负责设备通讯及总控,开发使用三
-

移动护理平台
针对临床护理工作设计与开发的一套平台,依托移动 PDA 与无
-

Crisis VR
使用electron打包桌面应用,通过调取自定义协议URLP
-

医院ITIL系统
主要为辅助医院信息科对工单进行管理。本系统包含服务申请、服务
-

医药 B2B 商城项目
医药 B2B 商城项目。使用了 CSS3 和 HTML5 的
-

健康管理平台
该产品主要针对的是本公司的常视康肠镜检查仪器做的一个人体健康
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

