
案例介绍
1.数据采集阶段-b站发现爬虫采集会封IP 使用代理IP 用时大概一周获取1500万数据
2.数据库sqlite3
3.启动run(URL+[i for i in range(1,1997*10000)]) 开启延迟避免封IP,判断code!=0
获取aid(视频编号),view(播放量),danmaku(弹幕数),reply(评论数),favorite(收藏数),coin
(硬币数),share(分享数),保存本地,报错保存logging
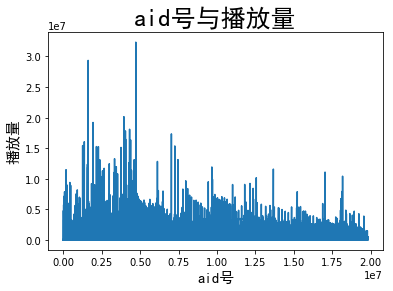
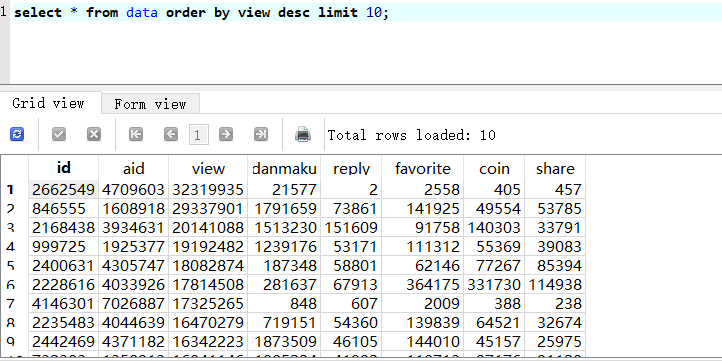
4.Pandas+sqlite3+matplotlib 分析数据关系,aid与播放量,收藏与硬币数,查询播放
量前10,查询收藏前10
案例图片
相似案例推荐
其他人才的相似案例推荐
-

影视数据分析系统
角色: 后端开发工程师(Node.js) 负责: 负责对项
-

电影系统+公众号系统
基于开源系统的改造 可以实现微信公众公众平台的管理,也可以
-

移动城市影票
无线城市手机影票应用程序,是服务于江西全省客户的电影资讯票务
-

喵看app
喵看是一款专注于电影的app,集行业资讯和影迷社交于一身。在
-

学而思小班课
学而思小班课APP是为学而思学员提供的专用于体验上课的iPa
-

某销售系统平台
主导开发改项目,完整项目包含管理系统和移动客户端,主要用于直
-

豆瓣观影
主要是利用豆瓣的开发接口,完成影片列表,以及影片的详情等功能
-

甜蜜语聊
APP独立开发 使用的架构是MVP, 语音视频交友,视频
-

乐到app
赛事活动模块:实现战队报名,战队随机匹配,冠军奖励,其他一些
-

乐到网站
网站后台管理设计开发主要包括:视频,图片上传,课程录入,后台
-

乐到网站
网站后台管理设计开发主要包括:视频,图片上传,课程录入,后台
-

twinkle
使用react-native开发,同时打包ios,andro
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

