
案例介绍
目的:针对客户端电子书应用存在正版收费的情况,对于新发布的小说文学作品在免费的情况下进行阅读
技术:python,requests,lxml,os, mysql
实现:通过获取到资源对应的网站链接,对网页结构进行分析,提取出需要的字段内容
难点:数据采集时因为采集频率过高触发网站断开响应,使用random+sleep随机1-3s休眠,爬取一段时间后网站仍会断开链接;
针对多次访问网页断开链接的情况,使用mysql数据库存储已经采集国的页面链接和总体的页面链接,网站断开服务后第二 次重新爬取判断爬取的网页链接是否在存储的页面链接中,成功解决。
案例图片
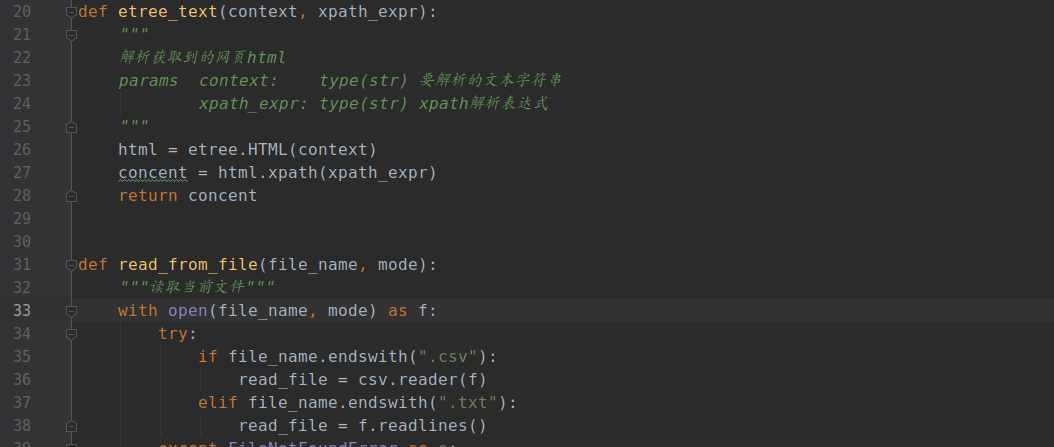


相似案例推荐
其他人才的相似案例推荐
-

简单心理
趣味测试,星座,占卜开发,WX公众号,各类小程序,短视频平台
-

漂吧图书
windows Linux 下的 共享图书平台。 开发
-

个人博客系统
基于开源项目 mBlog 搭建的个人博客,项目是基于 Spr
-

猿知识
猿知识是一个基于文化领域的交易、租赁、共享的服务创新平台,主
-

艺术一刻钟
艺术一刻钟是以全民艺术普及为目标,以精品艺术培训、鉴赏为内容
-

仙果体育
目前负责仙果科技公司下APP Web 等核心产品的视觉设计与
-

后台博客
1、系统核心功能 通过后台系统可以设置改网站的参数,比
-

掌阅
掌阅是国内知名在线电子书阅读器,用户量上亿。 担任书城,书
-

微信小程序
个人练手小程序,请求豆瓣Api 自适应rpx和分辨率Fle
-

requests库简单提取小说
小说出处 http://www.quanshuwang.c
-

果果女郎
果果女郎是一款手机美女模特写真照片app,这款软件签约上百位
-

社区
用户可以发表文章,也可以查看别人写的文章,并且对他的文章做出
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

