
案例介绍
PDF无表格线和有表格线表格抽取
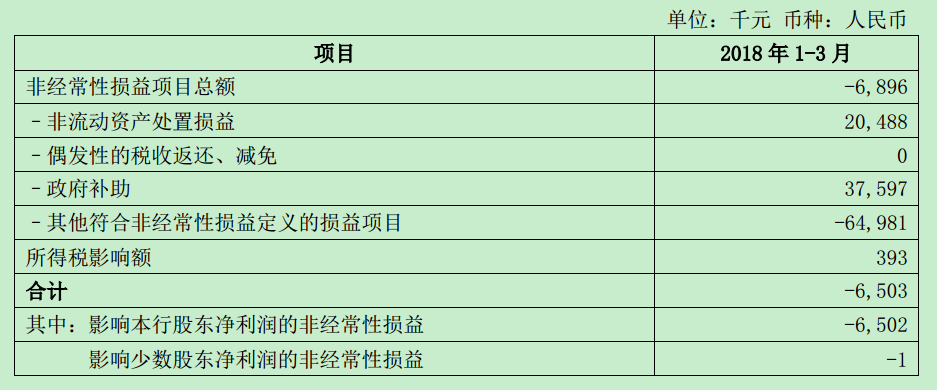
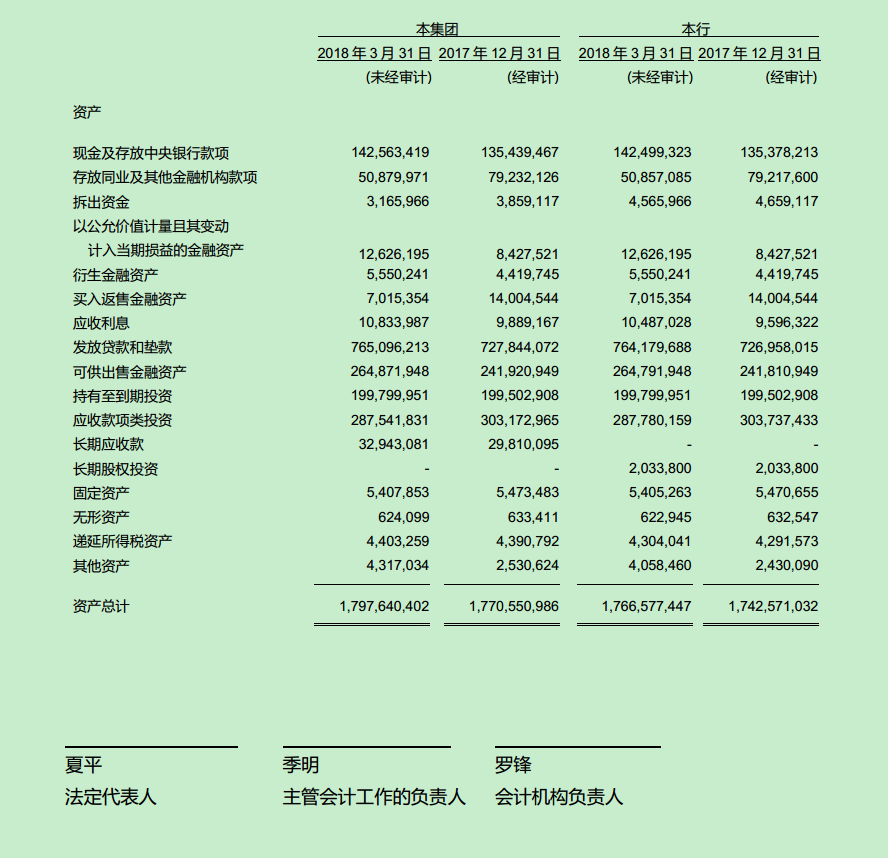
描述:从PDF中抽取无表格线表格和有表格线表格。上传PDF,对每一页利用ResNet进行图片分类,判断是否包含无表格线表格。然后对包含无表格线表格的页面,利用ALBERT进行文本分类,判断每一行是否属于表格,完成表格外框抽取。然后利用文字间隙和语义信息画表格内框线。有表格线表格采用Opencv抽取线条进行表格抽取。合并无表格线表格和有表格线表格结果作为pdf抽表结果。其中无表格线抽表经历了使用U-net进行像素分类,判断每一个点是黑色像素还是白色像素,进行画线;经历了使用Yolov3, Cornernet,Centernet等进行目标检测,采用目标检测的方法进行画矩形框抽取线条;行分类抽取外框和规则抽取内框等三个阶段,其中行分类抽取外框和规则抽取内框抽表结果最好。
标签:图像分类,文本分类,像素分类,目标检测
案例图片
相似案例推荐
其他人才的相似案例推荐
-

财富泉
财富泉是上海上证为做基金的朋友们而开发的一款手机应用.它包含
-

某后台的自动化网络爬虫
第一次用猿急送,不知道要提交了这么多次,感觉写的有点乱 不
-

百度股市通
百度股市通APP提供管理自选股,查看股票、基金详情,资讯,热
-

小工兵产品方案
担任产品经理职责,兼实施项目管理;作品中核心部分已经删除,不
-

模拟炒股
模拟炒股是金銮羊羊APP嵌入的H5形式的一个模拟炒股功能模块
-

金銮羊羊APP
金銮羊羊是一款集行情订阅、股票交易、资讯分享、股票孖展融资一
-

钱投顾
“钱投顾”致力于打造一个专业的股市投资者社区,通过整合专业投
-

量化交易
在聚宽量化交易平台,用python写的指数基金交易策略,年化
-

itrader
通过消息中间件实时获取各交易中心的交易数据,并对消息进行相应
-

摩尔金融App
此App为摩尔金融App,金融类平台 App当中的品牌色确
-

股票练习软件
web网页展示股票量价信息,财报信息;根据历史数据做买卖练习
-

asdf
fasdffffffffffffffffffffffffff
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

